
Recently we introduced the “Related” column prefix that allows seamless access to columns from related tables and really simplifies the settings when creating a dependent dropdown for a single-reference column.
Example: Many Interests
Let’s explore a scenario where managing a list of interests and hobbies becomes seamless and intuitive for users. Imagine having a plethora of interests and hobbies, each interest branching into various specific hobbies. The challenge lies in allowing users to select multiple interests while effortlessly navigating through associated hobbies. Here’s how we can tackle this.

We begin with a robust database consisting of three essential tables: Interests, Hobbies, and Many Interests.
Firstly, within the “Hobbies” table, we establish a reference column named [Interest]. This enables us to designate one parent interest for each hobby created, ensuring clarity and organization.
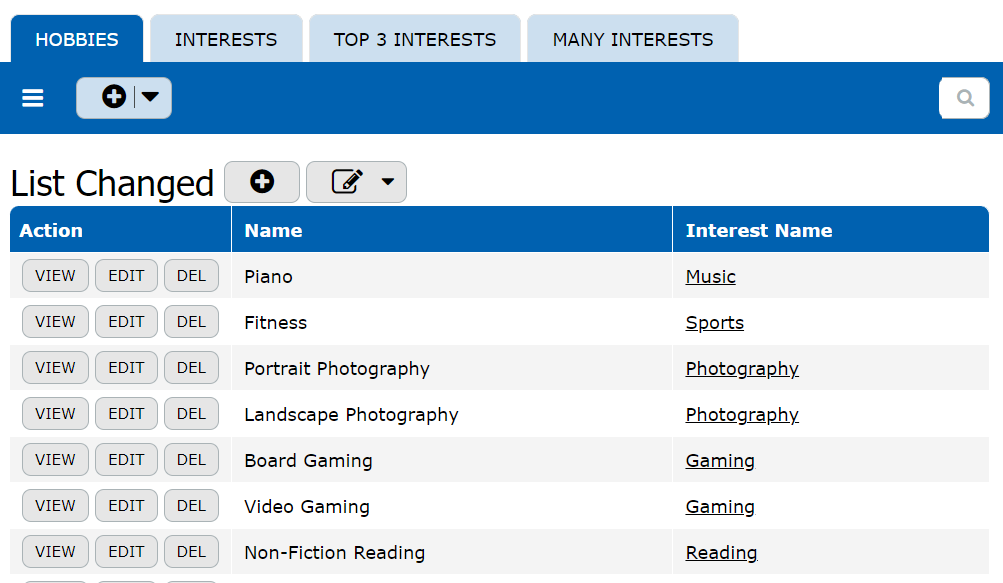
Next, we introduce the “Many Interests” table, designed to empower users to select multiple interests and subsequently choose several hobbies linked to those interests. This table features two multi-reference columns: [Interest] and [Hobby].
Now comes the ingenious part – configuring the [Hobby] column to display only relevant hobbies based on the selected interests. We achieve this by implementing a filter formula in the record picker: Any([Interest Name], Related[Interests]). This filter dynamically showcases hobbies aligned with the selected interests, streamlining the user experience.

Consequently, users gain the flexibility to cherry-pick several interests and explore a myriad of associated hobbies effortlessly. With this approach, managing interests and hobbies becomes not only efficient but also enjoyable for users navigating the system.

In this example we saw how we can create a dependent selection between two multi-reference columns.
Example 2: Top 3 Interests
At times, the need arises to select values independently across separate columns, while still maintaining dependencies, particularly when selecting hobbies. Let’s delve into how to accomplish this seamlessly.
To start, alongside our existing setup, we introduce a new table named “Top 3 Interests.” This table features three single-reference columns: [Interest 1], [Interest 2], and [Interest 3], along with a multi-reference column: [Hobbies].
Within the [Hobbies] column, we apply a filter formula in the record picker to establish dependencies: [Interest]=Related[Interest1] or [Interest]=Related[Interest2] or [Interest]=Related[Interest3]. This formula ensures that only hobbies associated with the interests selected in the [Interest 1], [Interest 2], and [Interest 3] columns are displayed.
And there you have it! Users will encounter a streamlined interface when creating records within the “Top 3 Interests” table.

By following these steps, you’ve acquired the know-how to effortlessly implement dependent selections for multi-reference columns, enhancing the user experience and system functionality.



Just recently I began to appreciate how useful Related[…] is. Now this new feature makes it even more useful. Thank you!
But I have been wondering also what precautions I have to take with regard to the performance aspect of Related[…]. You see, when running “Performance Tips”, if I have used “lookup” or “summary” columns in “match conditions” of a relation, I would be advised to change to using value columns. Now if I use “lookup/summary” with Related[…] in the filters instead of in the “match condition”, they don’t appear in “Performance Tips” (the last time I check). My question is: will this (ie lookup/summary columns and Related[…]) affect performance just like in “match condition”, and should be avoided?
The use of the Related[…] prefix can indeed affect performance, but because the system handles them in a different way, in most cases, it will work better or the same as match conditions. If we find some performance patterns related to the usage of the Related[] prefix, we’ll add a corresponding report to the performance tips.
That’s really nice! Thank you!